파이썬에 대한 이해

이 시리즈는 박상길님의 <파이썬 알고리즘 인터뷰> 자습서를 보고 공부한 내용을 담고 있습니다. 좋은 책 펴내주셔서 감사합니다.😊
나에게 항상 약점이였던 수학적 역량을 채워보기 위해 코딩 테스트 공부를 시작했다. 웹을 같이 공부하고 있어서 타입스크립트로 코딩 테스트 공부를 할까 고민도 했는데, 이 책의 내용을 보고 파이썬으로 결정을 내렸다. 책 초반 내용 중 파이썬 문법, 자료형에 대해 필요한 부분을 정리했다.
파이썬에 대한 이해
문법
타입 힌트
파이썬 버전 3.5 부터 타입을 지정할 수 있는 타입 힌트가 추가되었다.
# 변수
a: str = "1"
b: int = 1
# 함수
def fn(a: int) -> bool:lambda 표현식
lambda 표현식은 함수를 한 행에 정리해 둔 표현식이다. 아래의 함수와 labmda 표현식은 서로 같다.
def sum(x):
return x + 3
lambda x: x + 3lambda는 map이나 filter와 함께 자주 쓰인다. map은 요소 하나하나를 조건에 따라 변화시킬 때 쓰인다. filter는 조건에 대해 true인 요소만 남길 때 쓰인다.
# map
list(map(lambda x: x + 3, [1, 2, 3])) # 결과: [4, 5, 6]
# filter
list(filter(lambda x: x < 2, [1, 2, 3])) # 결과: [1]리스트 컴프리헨션
리스트 컴프리헨션(List Comprehension)은 기존 리스트를 기반으로 새로운 리스트를 만들어내는 구문으로, 파이썬 2.0부터 지원되었으며, 하스켈같은 함수형 언어에서 기능을 차용해온 파이썬의 대표적인 특징이기도 하다.
리스트 컴프리헨션은 lambda 표현식보다 더 유용한 기능이다. 리스트 안에서 조건을 자유롭게 넣어 구성할 수 있는데, lambda 표현식에서 구현했던 map과 filter를 리스트 컴프리헨션으로 구현하면 다음과 같다.
arr = [1, 2, 3]
# map
[ number + 3 for number in arr ]
# filter
[ number for number in arr if number < 2 ]제너레이터
제너레이터(Generator)는 … 루프의 반복(Iteration) 동작을 제어할 수 있는 루틴 형태를 말한다. 예를 들어 임의의 조건으로 숫자 1억 개를 만들어내 계산하는 프로그램을 작성한다고 가정해보자. 이 경우 제너레이터가 없다면 메모리 어딘가에 만들어낸 숫자 1억 개를 보관하고 있어야 한다. 그러나 제너레이터를 이용하면, 단순히 제너레이터만 생성해두고 필요할 때 언제든 숫자를 만들어낼 수 있다.
제너레이터는 데이터를 미리 다 만들어 놓지 않고, **필요할 때마다 하나씩 생성해서 반환하는 특별한 루틴”**이다. yield를 사용한 함수가 호출되면 바로 실행되는 것이 아니라 제너레이터 객체를 반환하고, 그 객체에 next()를 해야 비로소 코드가 실행된다. 제너레이터가 next()로 호출되어 yield를 만나면, 제너레이터는 해당 값을 반환한 뒤 함수를 종료하지 않고 그 자리에 일시 정지한다. 그리고 이후 다시 next()가 호출되면 멈췄던 부분 부터 다시 실행한다.
def count_to_three():
yield 1 # 여기서 1을 주고 멈춤
yield 2 # 여기서 2를 주고 멈춤
yield 3 # 여기서 3을 주고 멈춤
gen = count_to_three()
print(next(gen)) # 1
print(next(gen)) # 2range()
range()는 제너레이터의 방식을 활용하는 대표적인 함수이다. 기존에는 range()가 숫자를 미리 생성 해 리스트로 리턴하는 방식이였지만, 버전 3 이후 range() 함수가 제너레이터 역할을 하는 range 클래스를 리턴하는 형태로 변경되었다.
enumerate()
enumerate()는 ‘열거하다’는 뜻의 함수로, 여러 가지 자료형(list, set, tuple 등)을 인덱스를 포함한 enumerate 객체로 리턴한다.
a = [1, 2, 3, 2, 45, 2, 5]
list(enumerate(a)) # 결과값: [(0, 1), (1, 2), (2, 3), (3, 2), (4, 45), (5, 2), (6, 5)]인덱스와 함께 값을 활용할 일이 있을 때 enumerate()를 사용하면 깔끔하다.
for i, v in enumerate(a):
print(i, v)// 나눗셈 연산자
파이썬에서 //는 주석이 아니라 몫을 구하는 연산자다. (파이썬에서 주석은 #) 내림 연산자의 역할을 한다.
5 / 3 # 결과값: 1.6666666666...
5 // 3 # 결과값: 1C++의 참조와 비교
C++의 참조자(&)와 파이썬의 재할당은 다르게 동작한다.
int a = 10;
int &b = a;
b = 7;
// a를 출력하면 7이 나옴C++은 같은 메모리 주소 내부의 값을 바꾸는 것이라 a의 값과 b의 값이 항상 같다.
a = 10
b = a
b = 7
# a를 출력하면 10이 나옴파이썬의 int는 불변형이라, 다른 메모리에 새로운 숫자(7)의 객체를 할당하여 만든 후 b의 주소를 새로운 객체를 가리키게 바꿔 a와 b의 값이 다르게 변한다.
is와 ==
파이썬의 is는 id() 즉, 주소값을 비교하는 함수이다. ==는 값을 비교하는 연산자이다.
a = [1, 2, 3]
a == a # True
a == list(a) # True
a is a # True
a is list(a) # False자료형
불변형과 가변형
파이썬의 자료형은 불변형과 가변형으로 나뉜다. 여기서 변하는 것의 기준은 메모리 안의 데이터이다. 메모리에 이미 만들어진 데이터를 수정할 수 있으면 가변형, 수정할 수 없으면 불변형이다.
파이썬에서는 리스트, 딕셔너리, 집합을 제외하고 튜플 등 다른 자료형들은 모두 불변형이다. 문자열이나 숫자는 값을 바꿀 수 있어 가변형이라 생각할 수 있는데, 실제로는 문자열이나 숫자의 객체를 새로 만들어 참조 값을 바꾸는 것이기 때문에 메모리 안의 데이터는 바뀌지 않는다.
객체
파이썬의 모든 자료형은 객체이기 때문에, 원시타입을 가진 C나 Java와 비교하면 속도가 떨어진다. 예를들어 C의 int는 4바이트의 공간밖에 차지하지 않지만, 파이썬의 int는 적어도 28바이트의 공간이 필요하다. 파이썬의 int는 객체이기 때문에 객체에 관련된 헤더 정보가 필요하기 때문이다. 하지만 객체이기 때문에 개발자가 사용할 수 있는 메서드를 정의할 수 있고, overflow에 대한 걱정을 하지 않아도 된다. (자동으로 크기를 늘려줌) 파이썬에서 속도를 더 빠르게 사용하고 싶으면, 겉은 파이썬이지만 알맹이는 C인 Numpy를 활용할 수 있다. NumPy는 연속된 메모리 구조를 사용하여 CPU가 데이터를 읽어오는 속도가 빠르다.
리스트
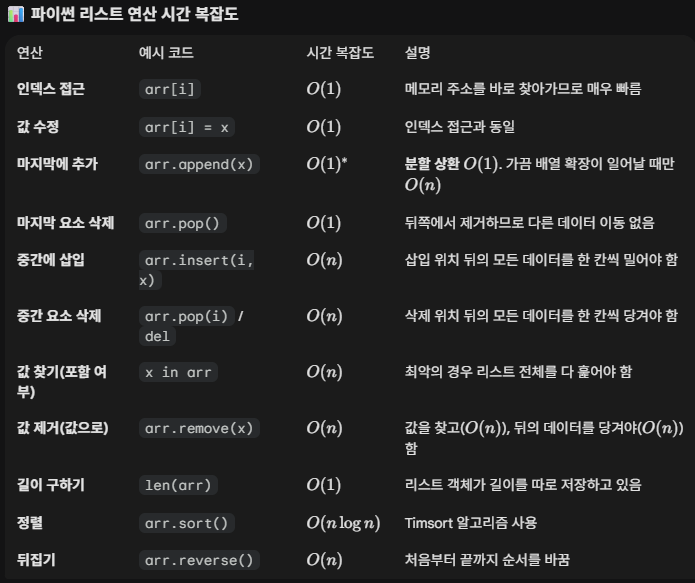
주요 연산 시간 복잡도
리스트는 끝에서의 작업이 빠르다.
예를 들어 append()와 pop()은 리스트의 끝에서 이루어지므로 매우 효율적이다(O(1)).
하지만 앞이나 중간에서의 작업은 느리다.
insert(0, x)나 pop(0)처럼 리스트의 앞부분을 건드리면 전체 데이터를 이동시켜야 하므로 리스트가 커질수록 성능이 급격히 떨어진다.
(이럴 때는 collections.deque를 사용하는 것이 좋다.)
딕셔너리
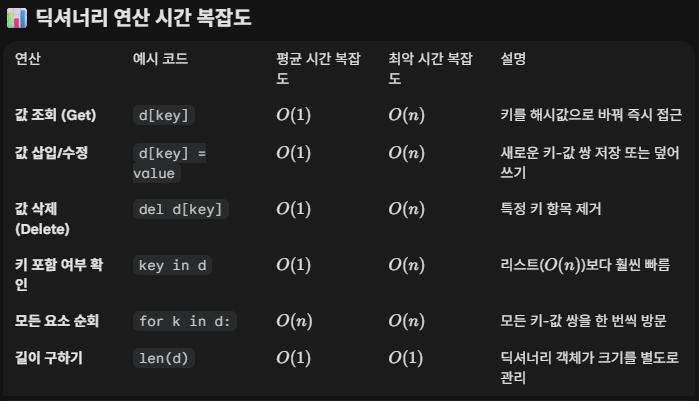
주요 연산 시간 복잡도
딕셔너리는 내부적으로 **해시 테이블(Hash Table)**이라는 자료구조로 구현되어 있어, 대부분의 연산이 데이터 양에 상관없이 매우 빠르게 수행된다.
딕셔너리 주의점
파이썬 3.6 이하에서는 딕셔너리의 입력 순서가 유지되지 않는다. 파이썬 3.7 부터는 딕셔너리의 입력 순서가 유지되도록 개선되었으나, 코딩 테스트에서 지원하는 인터프리터 버전이 명확하지 않을 때는 OrderedDict 등을 활용하는 것이 좋다.